There will now be a conference session where the Challenge results will be announced. Leading entrants will be invited to make a presentaion of their methods during this session. Please contact us if you are planning to attend the conference and would like to be considered as a potential presenter.
You have asked several experts to independently build you some mathematical models that will predict how your customers would rate particular movies. All the experts, who were given the same information on how previous movies were rated, provided predictions with very similar accuracies. While trying to determine which experts predictive methodology to use in your recommender system, you noticed that by simply averaging the predicted ratings of each expert, you ended up with a more accurate solution than any particular individual expert could produce alone.
As predictive accuracy is paramount, you now want to determine if there is a better way of combining the predictions than simple averaging.
The challenge is to find the most accurate method of combining your experts.
More Detail:Ensembling, Blending, Committee of Experts are various terms used for the process of improving predictive accuracy by combining models built with different algorithms, or the same algorithm but with different parameter settings. It is a technique frequently used to win predictive modelling competitions, but how it is actually achieved in practice maybe somewhat arbitrary.
One of the drawbacks in researching the problem is that you first have to generate a lot of models before you can even start. There have been numerous predictive modelling competitions that could potentially provide good data sets for such research - many models built by many experts using many techniques.
The Netflix Prize is one such competition that has been on going for nearly 3 years. It recently finished, and the eventual winners were an amalgamation of several teams that somehow combined their individual model predictions.
Over 1,000 sets of predictions have been provided by the two leading teams (who actually ended up with the same score), The Ensemble and BellKor's Pragmatic Chaos. The primary goal of this challenge is to stimulate research into 'Ensembling' techniques... but also answer the question many of us want to know - how low can Netflix go?
By way of an example, the chart below shows the individual RMSE of over 1,000 models provided. Taking the mean prediction over all these models is only slightly worse than the best individual model. The mean of the best 10 models is significantly better than any individual model.
The purpose of this challenge is to somehow combine the individual models to give the best overall model performance.
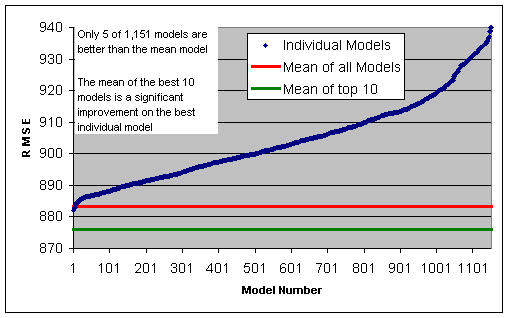
|
The data provided for this challenge comes from 1,151 sets of predictions of integer ratings in the range (1-5). Each set of predictions was generated by mathematical models with the objective (generally) to minimise the 'root of the mean squared error' (RMSE) over the full set of over 1.4 million ratings. To those familar with the Netflix Prize, each of these sets of predictions would be what is known as a probe file, and we collected 1,151 probe files altogether.
All the individual probe files were merged into one large file (1,151 columns, 1.4 million rows). Form this file, random sampling was used to generate 6 data sets for the challenge. Each of these data sets is split into 2 files, one for Training (Target/Rating provided) and one for Scoring (Target/Rating withheld). We will refer to the Rating as the 'Target' - the thing we are trying to predict.
There are 2 small, 2 large and 2 medium data sets. You can use the small data sets for developing your techniques. Your predictions of the Targets for the small data set Scoring files can be uploaded and and feed back will be given on the performance. It is the predictions of the Targets in the medium and large data set Scoring files that will be used to determine the winner - no feedback is available for these.
There are 2 tasks, one to develop a method to predict a continuous value and the other to predict a binary value. The metric used to detemine accuracy are different for each task.
In each of the data sets, the Training and Scoring files are of the same size:
- RMSE Small - 200 sets of predictions for 15,000 ratings. The objective is to minimise the RMSE.
- AUC Small - 200 sets of prediction for 15,000 ratings. Only ratings of 2 particular values are included (eg 1s and 5s), sampled with different weightings on each value. The objective is to minimise the AUC.
- RMSE Large - 1,151 sets of predictions for 50,000 ratings. The objective is to minimise the RMSE.
- AUC Large - 1,151 sets of predictions for 50,000 ratings. Again, these only include ratings of 2 particular values that may or may not be the same values used in the small set. The objective is to minimise the AUC.
- RMSE Medium - 250 sets of predictions for 20,000 ratings. The objective is to minimise the RMSE.
- AUC Medium - 250 sets of predictions for 20,000 ratings. Again, these only include ratings of 2 particular values that may or may not be the same values used in the small/large set. The objective is to minimise the AUC.
The data sets are csv files with header rows. The first 2 columns are rowID and Target (actual rating) and then either 1,151 or 200 columns of predicted rating values. In the Scoring files the Target values are zeros.
For both the RMSE and AUC tasks, the predicted ratings values have been converted to integers by rounding to 3 decimal places and multiplying by 1,000. Thus each predicted rating will be an integer and should lie in the range 1,000 to 5,000.
For the RMSE tasks, the same transformation was applied to the actual (Target) rating. Your supplied predictions should also be on this scale (ie the scale 1,000 - 5,000) but can also have decimal places.
For the AUC tasks, the Target values are 1 and -1 (zeros in the Scoring files). The actual values for your supplied predictions is not important, it is the rank order that matters.
The solution files should be a text file with no header row and 1 number per row (ie 15,000 or 50,000 rows). They should be sorted in order of rowID but rowID should not be included in the file.
You can submit entries for the AUC, RMSE or both tasks - there will be winners in each category (only on the large and medium data sets). You can submit multiple times, but your last submission will be the one that counts.
To be in contention to win, you must also provide a report (pdf format) outlining your methods. This can be as long or short as you like but should provide enough detail to give others a reasonable idea about how you approached the problem. If you submit entries for both tasks then only 1 report is required. Please include in the report your team name, team members and any affiliation. These reports will be made available on this site.
There will be also be a 'Grand Champion'. This will go to the team with the lowest average rank over both the AUC and RMSE submissions (where only the ranks of teams who have entered both tasks for both large and medium data sets are taken into account, with the large having twice the weighting of the medium). In the event of a tie, only the large rankings will be considered, if still a tie then the team with the lowest error on the large AUC problem will be declared the winner.
The 'Grand Champion' will receive $1,000 Australian Dollars.
Bragging rights only to the rest!
AUC - what is it?
The Area Under the Curve (AUC) is one metric to quantify how well a model performs in a binary classification task. Given that the thing we are trying to predict has only 2 values (eg Class A/Class B, 1/0 , red/not red, rating 1/rating 5), how well does the model separate these values. In the data provided, the two values are coded as 1 and -1. AUC is a pretty simple concept and easy to calculate...
Your model is trying to predict a value of 1 or -1. Sort your models predictions in descending order (that is the only role the predictions play!). Now go down the sorted list and for each prediction, plot a point on a graph that represents the cummulative % of class A v the cummulative % of class B that have actually been encountered upto and including that particular prediction. Join up all the points to form a curve. The AUC is the area under this curve.
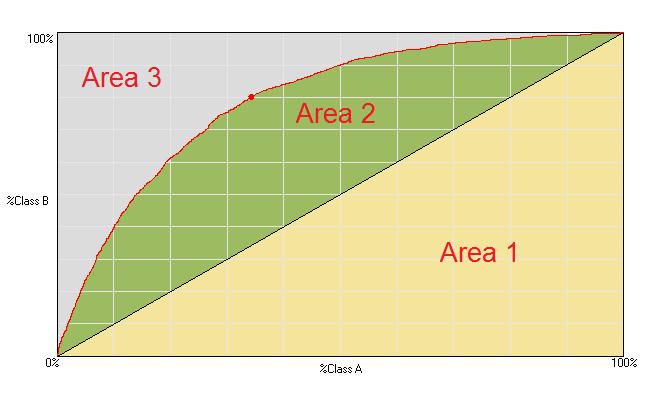
Area 1 + Area 2 + Area 3 = 1 (100%)
AUC = Area 1 + Area 2
Note that if the curve followed the diagonal line then the model has no ability to separate the 2 classes - it is no better than random. This would have an AUC of 0.5. An AUC of 1 is a perfect model (Area 3 disappears - 100% of class B have been found before any of class A) and an AUC of 0 is also a perfect (but backward) model.
A similar metric is the Gini coefficient, which is essentially the same but scaled so that 1 represents a perfect model, 0 a random model and -1 perfect but backward.
Gini = 2 * (AUC - 0.5)
For this challenge we will be calculating the absolute value of the Gini coefficient, which means you do not have to worry about whether your model attempts to assign higher scores to class A or class B.
We have include an Excel file on the download page that contains macro code to calculate the AUC.
September 21, 2009
Bellkor's Pragmatic Chaos announced as winners of the Netflix Prize receiving $1million.
September 26, 2009
Challenge begins. Teams can register, download the small data sets and submit solutions to the leaderboard.
October 7, 2009
Medium data sets made available.
October 18, 2009
Large data sets made available.
November 8, 2009
Final Solutions and Reports can start to be submitted.
November 22, 2009
Challenge closes. Deadline for submitting solutions on the large and medium data sets and uploading a report.
The submission page will close when it is no longer Nov 22nd anywhere in the world.
December 1-4, 2009
Results announced at AusDM 2009 Conference.
Who can enter?
- Anyone, even the experts who supplied us with the rating predictions (and we hope they do).
What about teams?
- You can enter either individually or as a member of a team - but not both. No individual can be in more than 1 team. Any large commercial organisations submitting multiple entries via single person teams will be disqualified.
Supporting code
- There is an Excel file on the download page that will calculate the AUC with VBA code showing how it's done.
- We have also prepared a Visual Basic 2008 project that you can use as a framework. It prepares the data for fast loading and demonstrates very simple hill climbing and gradient descent methods. It will also automatically generate a submission file for the built models, so you can easily make submissions using the given algorithms and included executable. VB2008 Express Edition is available for free here. You might need to install the latest version of the .net framework if you just want to use the executable.
Literature
Please contact us with any relevant online research literature that may be useful and we will add it to the list below.
Y. Koren, "The BellKor Solution to the Netflix Grand Prize", (2009) [see Section VII].
A. Toscher, M. Jahrer, R. Bell, "The BigChaos Solution to the Netflix Grand Prize", (2009). [see Section 6]
M. Piotte, M. Chabbert, "The Pragmatic Theory Solution to the Netflix Grand Prize", (2009) [see Section 4].
Its already been calculated what a 50/50 blend of BPC and The Ensemble submissions would have achieved. Read more here.
IBMs winning entry in the 2009 KDD Cup reference the following:
Ensemble Selection from Libraries of Models
Getting the Most Out of Ensemble Selection
Team Gravity made their linear regression code available to all Netflix participants.
Analysis of the PAKDD 2007 Competition entries
Many thanks to Netflix for organising the Netflix Prize and allowing us to redistribute their rating values.
(Note that this challenge is not endorsed by Netflix in any way. They gave permission to use some of their data but are otherwise uninvolved.)
To Gabor Takacs, Greg McAlpin and Andreas Toscher for organising the file collection and being enthusiastic about this challenge.
Your expert model builders - for 3 years of hard work:
The Ensemble
BellKor's Pragmatic Chaos
Gabor Takacs, Istvan Pilaszy, Bottyan Nemeth, Domonkos Tikk, Lester Mackey, David Lin, David Weiss,
Joe Sill, Ces Bertino, Gavin Potter, William Roberts, Willem Mestrom, Bob Bell, Chris Volinsky, Yehuda Koren, Andreas Toscher, Michael Jahrer, Martin Piotte, Martin Chabbert, Xiang Liang, Jeff Howbert, Chris Hefele, Larry Ya Luo, Aron Miller, Craig Carmichael, Bo Yang, Bill Bame, Nicholas Ampazis, George Tsagas.
If you have any questions please contact Phil Brierley via Email
Note that this is a free forum board and has a bit of downtime, so please be patient.
Please explain this AUC problem a bit more?
The AUC is just a common metric for determining how good a model is when the outcome is binary, we could quite easily have chosen the RMSE as the metric used to determine the winner.
Not many 'off the shelf' algorithms seek to minimise the AUC directly, but generally speaking, improving the performance of one metric will tend to improve on all metrics.
You will see in a previous competition that there were 4 metrics to optimise. The leading Tiberius entry submitted the same solution for all 4 tasks.
So if you treat it as a linear regression problem and try to minimise the RMSE, then you should also be getting a decent AUC at the same time.
In the supplied VB code we provide a hill climbing algorithm that seeks to maximise the AUC directly.
Does the AUC submission file just have to contain 1s or -1s ?
No, it can contain numbers of any value.
You are trying to rank order them, not assign a particular value.
Do I need to submit the actual rank orders in the AUC file ?
No, the calulation algorithm sorts all this out. Just submit a file where the higher the number means the greater propensity. You don't even have to worry about whether high numbers mean greater propensity to be 1 or -1, this is all dealt with by the calculation algorithm.
![]()
If you are interested in the outcome of this research and would like to encourage the competitors by contributing to the prize fund (and getting your name here) then please get in touch.
